Kubernetes Dashboard 보안 접속
native Kubernetes monitoring tool
설치
Kubernetes Deployments
- 클러스터에서 컨테이너화된 애플리케이션을 관리하기 위한 빌딩 블록 제공
- 애플리케이션 → 컨테이너 → Pod → ReplicaSet → Deployment
- 복제 Pod집합을 관리 및 확장하는 선언적 방법을 제공하는 API Resource로 상위 수준의 Object
이점
- 원하는 상태를 지정하면 Deployments Controller가 현재 상태를 원하는 상태로 조정 및 유지 → 지정된 수의 Pod replicas가 항상 실행되도록 보장 → Pod의 지속적 상태관리(Desired state management)
- ReplicaSet rollout을 통한 Pod 복제 및 Image 버전관리
- Workload(CPU, Memory usage) 기준 수동 및 자동 확장, 축소 기능 구현(HPA)
- Rolling update를 통한 중단 없는 업데이트 지원
- 다양한 배포 전략 제공
- 이전 버전(Rollback) 지원(revision)
- 사용하지 않는 ReplicaSet 정리
deployments-sample.yaml
Kubernetes HPA (Horizontal Pod Autoscaler)
- 수평적 Pod 자동 조정기(scale-out)로 시스템의 가동 상황에 맞춰 시스템을 유연하게 확장 축소
- CPU, Memory 사용량을 관찰하여 Deployment, ReplicaSet, StatefulSet의 Pod 개수를 자동 확장(DaemonSet 제외)
- 컨트롤러는 관찰된 평균 CPU 사용률이 사용자가 지정한 대상과 일치하도록 Deployment에서 replicas 개수를 주기적으로 조정
- 워크로드의 크기를 수요에 맞게 자동으로 스케일링하는 것이 목표
HPA 매커니즘, 적정 Pod 개수 지정 알고리즘
- HPA 컨트롤러는 원하는(desired) Metric값과 현재(current) Metric값 사이의 비율로 작동
- Metric값이 200m이고 원하는 값 100m 인경우 200.0/100.0 == 2.0 이므로 복제본 수가 두배가 됨
- Metric값이 50m 이면 50.0/100.0==0.5이므로 복제본수를 반으로 줄임
- 조정할 레플리카 갯수 =
ceil [ 현재 레플리카 갯수 * ( 현재 Metric / 원하는 Metric) ] - 주로 Deployment에 연결하고, 옵션으로 resources를 반드시 포함해야한다.
작동 순서
- metric 수집
- metric server가 집계
- 수집한 정보(metric) APIserver에 전달
- APIserver가 HPA에 전달(Get Memory, CPU → default: 15sec)
- HPA가 Replicaset에 전달
- Replicaset이 scale 정보를 APIserver에 전달
- etcd에 기록, scheduler가 Pod 생성 node 지정
- Node kubelet이 scale 정보확인
- Pod 생성 / 축소 (scale in/out)
HPA를 위한 metric server 구성
Kubernetes Job & CronJob
- Job는 Pod와 같은 종류지만, Pod와 다르게 특정 작업만 수행하고 종료된다.
- Job는 일회성 및 일괄 작업 실행에 적합, CronJob은 반복작업 예약하는데 사용
- Job은 작업을 정의하고 완료될 때까지 실행되도록 보장, 하나 이상의 Pod의 수명 주기를 관리하여 원하는 성공횟수가 도달할때 까지 관리
- CronJob리소스는 사전 정의된 일정(매시, 일일, 주간, 월간 등)에 따라 Job 생성
- CronJob에 의해 생성된 각 Job은 특정작업 또는 작업 집합을 Pod로 실행
- 백업, 보고서 생성 등과 같은 정기적인 예약 작업을 수행하기 위해
- 작업을 시작해야하는 특정 시점이 존재하는 경우
- 리눅스 cronjob과 동일 한 스케쥴 작성( 분, 시, 일, 월, 요일)

Kubernetes Label & Selector
복잡하고 다양한 Pod를 효율적인 집합으로 다루기 위한 방법으로 Label 사용
- Key-Value 기반의 속성 tag로 하나 이상 설정 가능
- 용도에 따른 리소스 선택시 유용 → 객체를 식별하고 그룹화
- Pod는 Label을 가질 수 있고, 검색조건에 따라 Pod를 특정 가능
- Label로 선택된 특정 Pod만 배포 업데이트 또는 접근권한을 부여하는 작업 가능
Kubernetes Namespace
Kubernetes cluster 내에서 리소스(Pod, Service 등)를 구분 및 경리 하기위한 가상의 논리적 공간(그룹, 파티셔닝)을 제공 → scope
- 서비스(애플리케이션, 팀, 환경등 목적에 따라 구분)단위의 Namespace 구분은 전체 프로젝트 운영 , 관리 측면에서 유리
- 개발 / 테스트 / QA / 운영 등의 목적에 따른 ns 구분
- 팀 내부의 업무별 구분 → frontTeam-dev / frontTeam-test / backTeam-ops
- NS를 통해 격리가 가능하기에 서로 간섭없이 실행 가능
- 클러스터 전반에 걸쳐 사용되는 object인 Node, PV, Namespace등은 Kubernetes에서 사용되는 저수준의 object로 NS에 의해 구분되지 않음
- kubectl api-resources –namespaced=true → ns에 포함되는 리소스
- kubectl api-resources –namespaced=false → ns에 포함되지 않은 리소스
- 일반적으로 사용되는 deployments, pod 등의 api-resource는 NS에 의해 구분
- NS별 접근제어(RBAC) 및 자원 소비 제어(ResourceQuata 등) 설정 가능
- 클러스터 및 NS 수준의 RBAC 구성(RoleBinding, ClusterRoleBinding)을 통해 리소스, 사용자간의 접근제어 구현 및 이를 통한 기본 보안 강화
- 민감한 데이터나 리소스에 대한 무단 액세스를 방지하는 동시에 여러팀이 Namaspace 내에서 작업할 수 있도록 허용
- ResourceQuota는 NS가 사용 가능한 최대 리소스 양을 지정하여 특정 애플리케이션의 자원 독점을 방지하여 다른 애플리케이션의 상대적 성능저하 방지
- 주로 CPU, Memory, Pod 수 등을 제한
- ResourceQuota는 NS에 사용 가능한 총 리소스
- LimintRange는 NS내 실행되는 컨테이너에 대한 제한을 할당 하는 데 사용
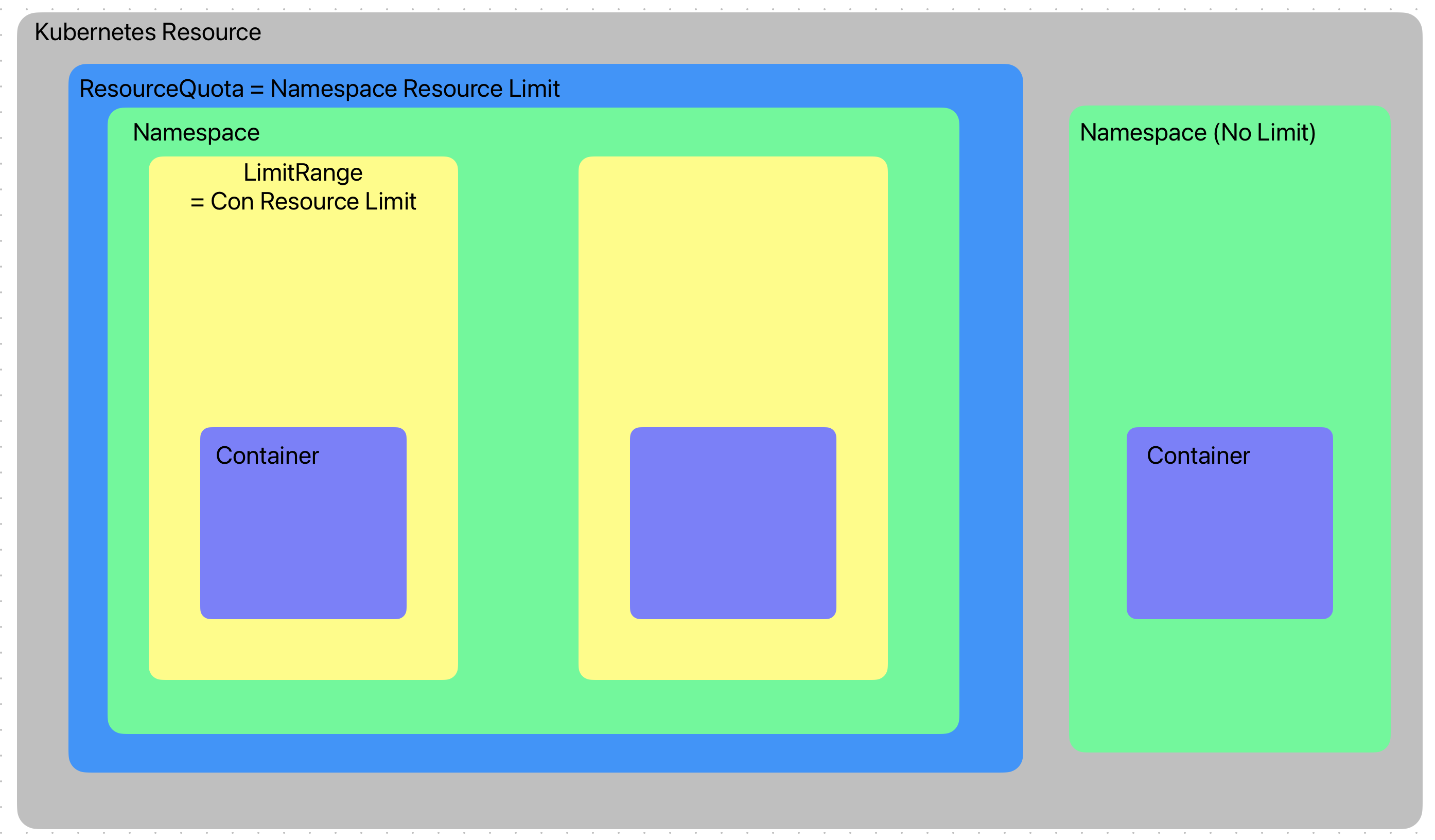
Kubernetes Namespace - ResourceQuota & LimitRange
Kubernetes Namespace에서 이어집니다.
NS별 자원 소비 제어를 위한 두 가지 오브젝트 → ResourceQuota, LimitRange
- ResourceQuota: NS가 사용 가능한 총 리소스 상한선 설정
- 특정 애플리케이션의 자원 독점을 방지 → 다른 애플리케이션의 상대적 성능저하 방지
- CPU, Memory, Pod 수, PVC 수, Service 수 등 제한 가능
- LimitRange: NS 내 개별 컨테이너 또는 Pod에 대한 기본값(default) 및 제한값 설정
- 컨테이너에 requests/limits 미지정 시 자동 적용되는 기본값 설정 가능
- 최솟값(min), 최댓값(max), 기본값(default), 기본 요청값(defaultRequest) 설정 가능
ResourceQuota
resourcequota.yaml
Kubernetes Node Schedule (NodeSelector, Affinity, Taint)
- Kubernetes가 커짐에 따라 스케쥴링(노드 할당)관리가 필요
- kube-scheduler : Pod가 할당될 Node관리
- 사용자가 원하는 Node에 아래를 통해 설정가능
- nodeSelector: 지정 Node에 배치요청 → deprecated 예정
- nodeName: 해당 node kubelet에게 직접 요청 → deprecated 예정
- Affinity(친밀도): 다양한 조건으로 Node배치 요청
- Tolerations: Taint(잠김) 설정된 Node에 강제 허용 요청
- schedulerName: Multi Schedule 환경인 경우
예시
Kubernetes Secret
비밀번호, OAuth 토큰, API 키, TLS 인증서, ssl키 와 같은 민감한 Credential이 요구 되는 데이터를 base64로 인코딩 하여 저장, 관리
- 데이터 저장은 1MiB 이하로만 가능
- Pod에 Secret 적용시 자동 Decoding되어 애플리케이션에서 바로 사용 가능
- 기본 사용방법은 configMap와 동일 → Kubernetes configMap 확인
- kubectl create cm → kubectl create secret
- envFrom.configMapRef → envFrom.secretRef
- name → secretName 로 바꿔 사용
Secret Pod
Kubernetes Service - Ingress
- Ingress object는 http, https 경로를 서비스에 노출하고 트래픽 규칙을 정의
- Ingress Controller를 사용하여 로드 밸런서를 통해 수신 규칙 및 요청을 이행(Ingress 사용시 전제 조건)
- Nginx Controller, Envoy Controller, Traefik Ingress Controller 등
- AWS Load Balancer Controller(EKS 사용시)
- Ingress object를 사용하면 로드 밸런서의 수를 줄일 수 있다.
- Ingress object 및 Controller를 사용 시 서비스당 로드밸런서 하나에서 Ingress당 로드밸런서 하나로 전환하고 여러 서비스로 라우팅이 가능하며 트래픽은 경로기반 라우팅을 사용하여 적절한 서비스로 사용이 가능하다.
Ingress
- L7, http/https 서비스 지원
- 서비스 유형이 아닌 여러 서비스 앞에 있다.(스마트 라우터) → 클라우드 진입 점 역할
- Ingress는 L7(http/https)계층 경로를 inbound traffic access(rule)를 사용하여 클러스터 내의 Service object에 쉽게 연결
- Kubernetes 내부 처리 과정
- 외부 트래픽(Internet) → Ingress(routing rule) → one or more Services → one or more web APP Pods → container
- Ingress는 단일 접점과 서비스 라우팅
- Service는 Pod 로드 밸런싱
- Pod는 비즈니스로직 처리하는 역할
- 외부 트래픽(Internet) → Ingress(routing rule) → one or more Services → one or more web APP Pods → container